Pet-Adopter Matching Machine Learning Project (Academic)
For a class project, my team and I were tasked with using big data to solve a real-world problem. This is our unique solution to a persistant issue in the pet adoption space.

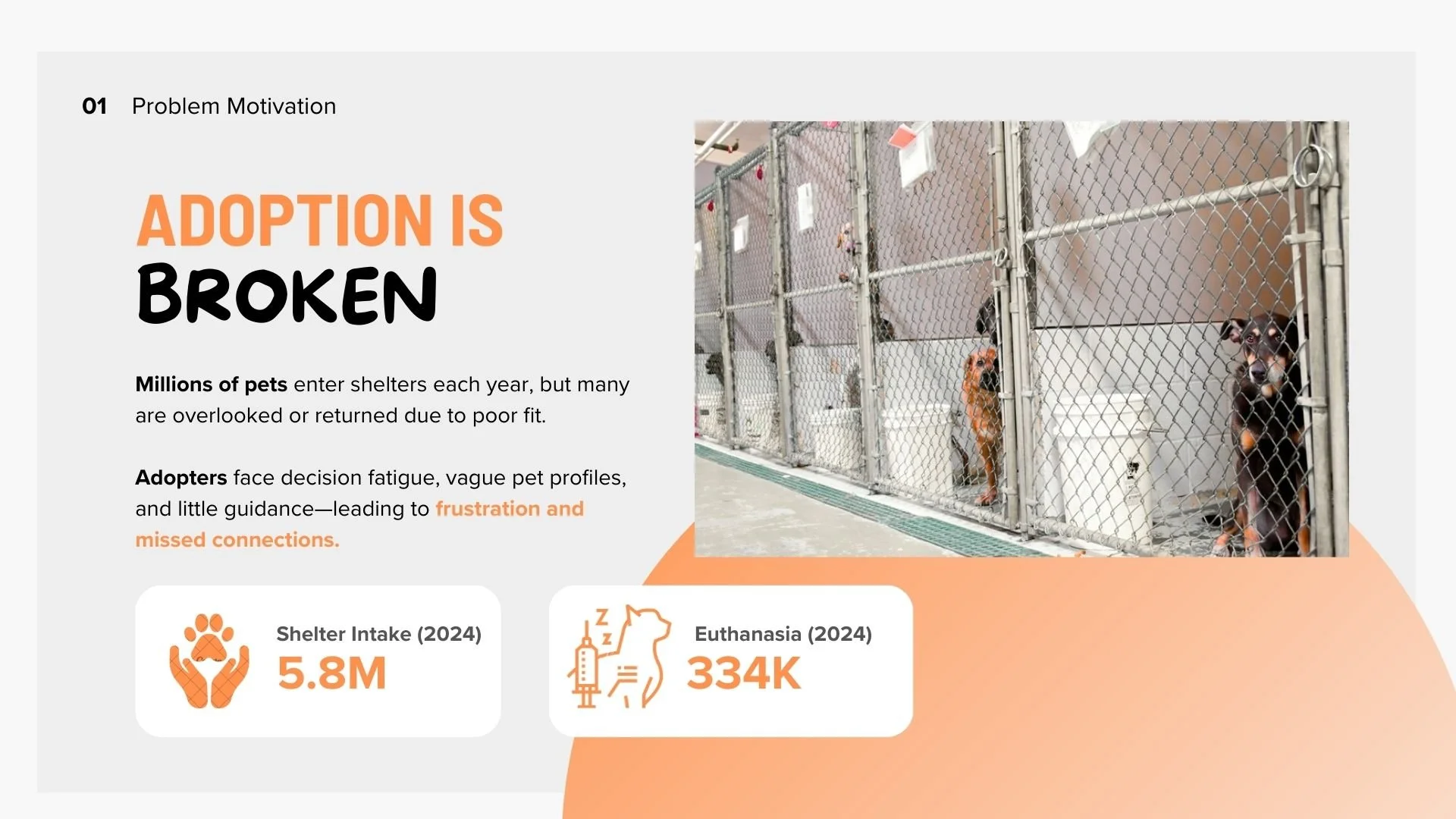






Background
We took on this project in response to the rising number of animals that remain in shelters without adoption. The trend risks overwhelming shelters in the Bay Area and across the country. Larger shelters can absorb higher intake due to their infrastructure, while smaller shelters face harder choices. Some are forced to turn animals away, and in the worst cases may consider euthanasia because intake is simply too high and resources cannot keep up.
Data Foundation and Pre-processing
With the context set, the next step was to build the data I needed to test pairing logic at all. Real adopter data was not readily available, so I started by creating a small but consistent table of adopter personas. Using Python with Faker in Google Colab connected to Spark, I sampled practical attributes such as age, housing type, activity level, and prior pet ownership. That work produced adopters_silver, stored in Google Cloud Storage at gs://pairing-demo-bucket/Adopters/.
In parallel, I prepared the other half of the match. I loaded an existing dataset of adoptable pets, explored its schema, and confirmed it was stable enough to combine with the adopter table. This pets_silver dataset lives in Google Cloud Storage at gs://pairing-demo-bucket/pets_silver/.
Once both sides were in place, I generated training examples. I cross-joined adopters and pets, scored each pair with a simple rule-based function, and applied a threshold to label matches as good (1) or bad (0). I first prototyped this flow in a local notebook (~/Downloads/Dataset_Creation_and_Loading.ipynb) and then operationalized it in PairGCPLoad.py. The script uses pandas for processing and interacts with Google Cloud Storage, producing train_pairs.parquet at gs://pairing-demo-bucket/train_pairs.parquet/. The output includes engineered features for both adopters and pets, along with the binary label that feeds the recommendation model.
There were a few important adaptations along the way. I configured the GCP environment for bucket creation and permissions so the pipeline had a reliable place to read and write. Early tests with Dataproc Serverless ran into CPU quota limits, so I pivoted to a pandas workflow with gcsfs for simpler and more efficient I/O at this stage. I also adjusted the pairing script to handle data variability, such as the missing “Weight (lbs)” column in pets_silver, by removing weight-dependent features and neutralizing the size component in scoring.
Recommendation Model
With the training pairs in place, I moved from data to decisions. The goal here was simple to say and harder to do: predict adopter-pet compatibility with enough signal to be useful
I chose a Wide and Deep model because it balances two needs. The wide side memorizes direct feature interactions you want the model to remember. The deep side generalizes from dense signals and embeddings so it can see beyond exact matches. I implemented this in TensorFlow Keras, following the spirit of tf.estimator.DNNLinearCombinedClassifier, and trained it in 03_train_wd_model.py.
The input to training is the train_pairs.parquet dataset produced earlier at gs://pairing-demo-bucket/train_pairs.parquet/. I downloaded it locally to /Users/jeremy/BigDataProj/model_training/data/train_pairs_local/, load it into a Pandas DataFrame, then convert to a tf.data.Dataset for efficient input pipelines.
On the architecture side, the wide component handles sparse, often one-hot encoded features such as pet breed, color, and adopter housing. The deep component is a DNN that learns from dense numerical features like pet age and adopter age, and it also uses embeddings for categorical inputs. Training runs through tf.data with callbacks for early stopping and model checkpointing, saving the best checkpoint by validation AUC.
For evaluation, I hold out 20 percent of train_pairs.parquet for testing. The model achieved a test loss of 0.0824, test accuracy of 0.9686, and test AUC of 0.9962. After validation, I serialize the model as pet_model.h5 in /Users/jeremy/BigDataProj/model_training/ and upload it to gs://pairing-demo-bucket/models/pet_model.h5.
There were a few bumps on the way to a clean training loop. Early runs threw ValueError exceptions from input shape mismatches. Keras Input layers were defined with shape=(1,), which expects two-dimensional tensors shaped like (batch_size, 1), while the dataset was yielding one-dimensional tensors shaped (batch_size,). I also ran into a normalization issue: tf.keras.layers.Normalization.adapt() was called on 1D arrays and learned the wrong internal shapes. The fix was consistent reshaping. I reshaped numerical features from (num_samples,) to (num_samples, 1) before calling adapt(), and in prepare_dataset I reshaped both numerical and categorical feature arrays to (num_samples, 1) so the dataset and model agreed on rank throughout the pipeline.
The result is a trained Wide and Deep recommender with a stable input pipeline and reproducible checkpoints, saved locally and in GCS for the next stage.
Streamlit Demonstration Application
With a trained model in hand, I built a Streamlit demo to make the system tangible. The goal is simple to experience: set an adopter profile, click a button, and see a ranked list of pets with a clear, one-screen explanation of why each match makes sense.
Under the hood the app uses Python, Streamlit, TensorFlow, Pandas, and the openai library for explanations. It loads the trained model (pet_model.h5), reads pet details from pets_silver, and pulls adopters_silver.parquet to populate dropdowns for adopter characteristics. Using the same vocabulary as the training data keeps inputs consistent with what the model expects. The OpenAI API (for example, GPT-3.5 Turbo) powers concise match rationales and is configured via Streamlit secrets.
The workflow is straightforward. In the sidebar, a user selects their profile attributes. On “Find Matches,” the app feeds the profile and pet data through the model to produce scores and a ranked list. Each recommendation is shown with its details and match score. For every item, the app requests a short, plain-English explanation from the OpenAI API that highlights why the pet could be a good fit.
There were a few practical iterations. Earlier local Llama experiments and TensorFlow dtype mismatches are part of the project history, but they are now superseded by the OpenAI-based explanation flow and refactors that improved batch processing and data handling. I also resolved a Streamlit startup error by ensuring st.set_page_config() is the very first Streamlit call in app.py.


Conclusion
This project started with a clear need and ended with a working path forward. We framed pet adoption as a compatibility problem, built the data to study it, trained a model that can score matches, and wrapped it in a simple app that lets someone set a profile and see why a pet might be a fit. It is an MVP by design, but it is an end-to-end one that connects problem, data, model, and experience.
The results are encouraging. The system generates recommendations in real time and explains them in plain language. Evaluation on a holdout set shows strong signal, with test accuracy at 96.86 percent and test AUC at 0.9962. The pipeline handled pairing at scale while keeping the app responsive, which suggests the approach can grow beyond a classroom prototype.
There were constraints and we met them head-on. Where real adopter data was not available, we used consistent synthetic profiles to bootstrap the problem. When infrastructure limits and shape mismatches appeared, we simplified, reshaped, and moved forward. Where fields like weight were missing, we adjusted features and neutralized the impact. The theme is consistent: solve the next concrete problem, keep the system honest, and preserve clarity for the user.
What comes next is focused and practical. The app is built to be plug-and-play for shelters with limited technical staff, with explanations that reduce black-box concerns. The real unlock will come from retraining on actual adopter behavior and adding feedback signals such as thumbs up or down on matches. That closes the loop between recommendations and outcomes, and it gives shelters a tool that learns with them over time.
In short, the work shows that a data-supported approach to matching can reduce friction for adopters, lighten the load for shelters, and give more animals a stable home. That is a result worth scaling.
How the project was received
“End-to-end solution that marries Spark-generated synthetic adopter data, a Wide & Deep matching model, Streamlit UI, and LLM-based rationales shows strong creativity and polished engineering.”
— Pantelis Loupos, Big Data Professor, MSBA Program, UC Davis.